
Qwen3-TTS: The Next-Generation Open-Source AI Speech Model
Generate hyper-realistic speech, clone voices instantly, and design unique audio personas with the power of Qwen3-TTS. The most advanced open-source text-to-speech model, now available online.
Introduction to Qwen3-TTS
Qwen3-TTS is a versatile engine fluent in 10 global languages, including Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian. Beyond standard translation, it offers precise control over dialect and tone. The model excels at understanding context, allowing it to adapt speaking rates and emotions on the fly while effectively filtering out noise from imperfect input text.
Next-Gen Acoustic Modeling
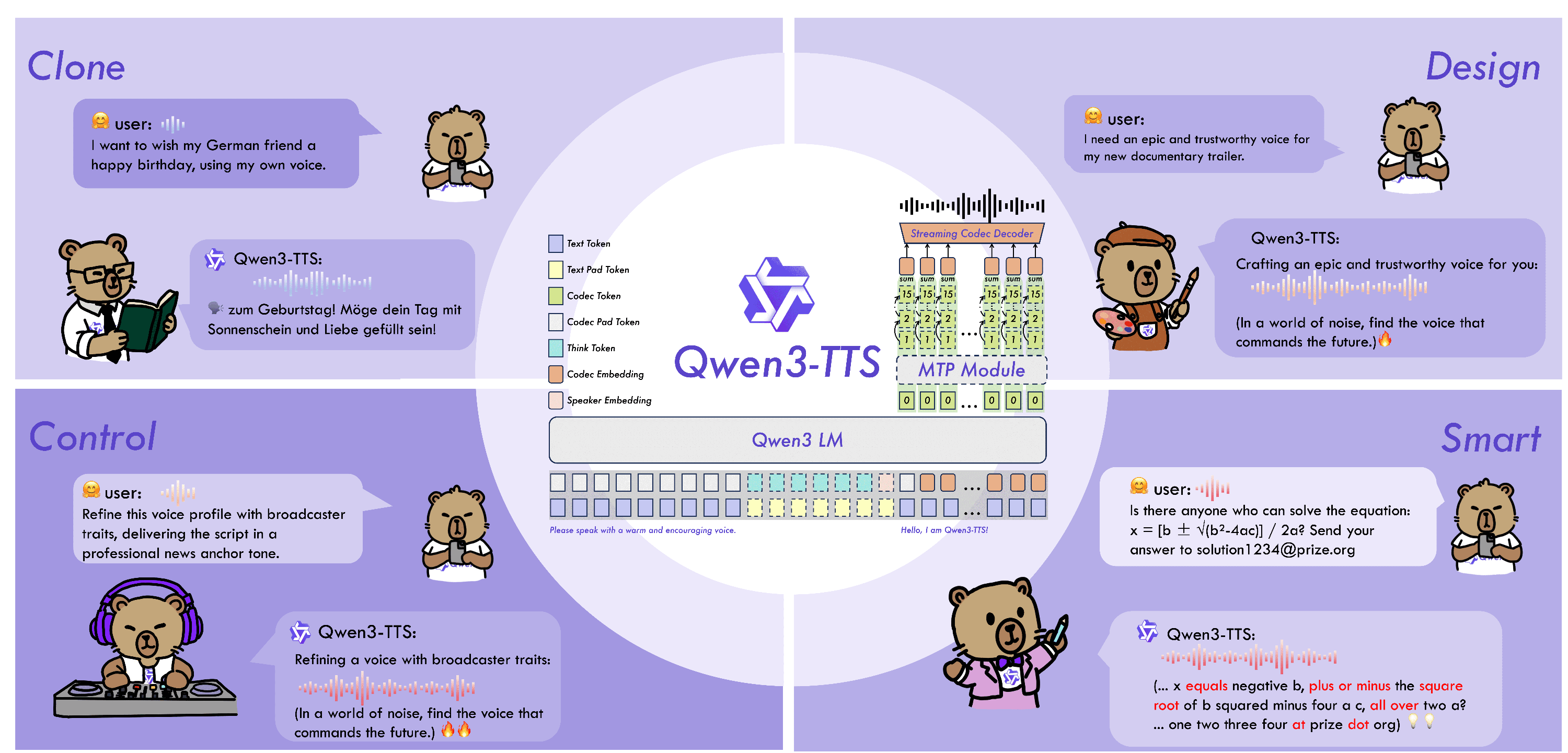
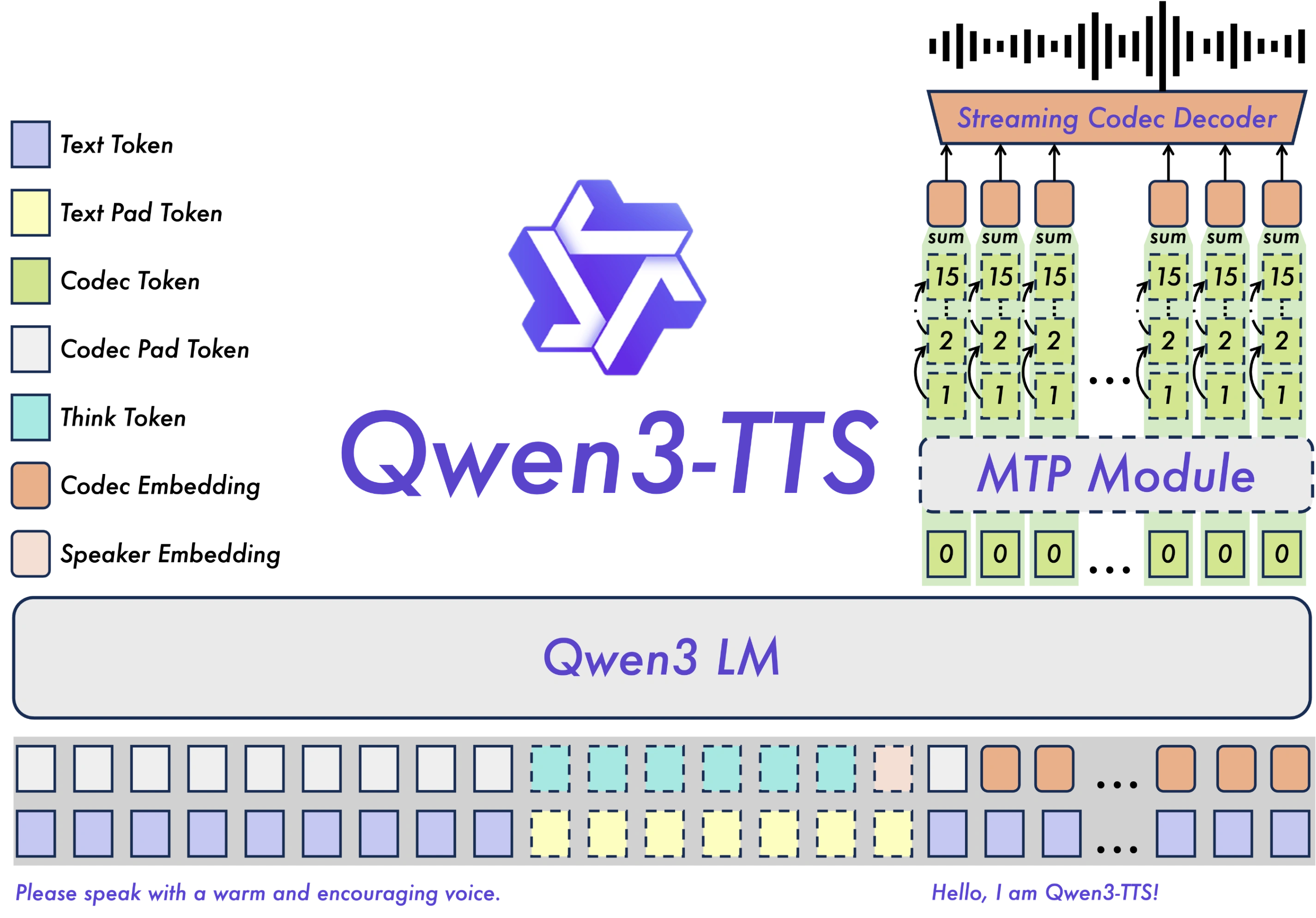
Built on the proprietary Qwen3-TTS-Tokenizer-12Hz, this system delivers superior acoustic compression. By utilizing a streamlined non-DiT framework, it captures subtle paralinguistic details and environmental sounds, ensuring high-fidelity audio reconstruction without the computational bulk.
Seamless End-to-End Design
Our discrete multi-codebook LM design enables true end-to-end speech modeling. This approach eliminates the information loss and cascading errors found in traditional LM+DiT pipelines, resulting in a significantly higher performance ceiling and greater generation efficiency.
Instant Streaming Response
Powered by a unique Dual-Track hybrid architecture, Qwen3-TTS bridges streaming and non-streaming modes. Achieving an industry-leading 97ms latency, it begins synthesizing audio after receiving just a single character, making it perfect for real-time interaction.
Prompt-Driven Voice Control
Direct every acoustic nuance through natural language prompts. The model deeply analyzes text semantics to adapt rhythm, timbre, and emotion dynamically, delivering a "what you imagine is what you hear" experience that feels genuinely human.
Qwen3-TTS Model Architecture
Qwen3-TTS utilizes a discrete multi-codebook LM architecture to realize full-information end-to-end speech modeling. This design completely bypasses the information bottlenecks and cascading errors inherent in traditional LM+DiT schemes. Based on the innovative Dual-Track hybrid streaming generation architecture, a single model supports both streaming and non-streaming generation, ensuring high efficiency and performance.
Released Qwen3-TTS Models
Explore the complete suite of pre-trained Qwen3-TTS models. Whether you need the raw power of the 1.7B parameter flagship or the efficiency of the 0.6B lightweight version, Qwen3 have a checkpoint tailored for your deployment needs.
Qwen3-TTS-Tokenizer-12Hz
Core ComponentThe essential neural codec foundation. It compresses continuous speech signals into discrete tokens and decodes them back with high fidelity, serving as the backbone for all generation tasks.
1.7B Flagship Series
Best Quality & ControlQwen3-TTS-12Hz-1.7B-VoiceDesign
Engineered for prompt-based persona creation. Describe a voice (e.g., "An old wizard") and generate it instantly.
Qwen3-TTS-12Hz-1.7B-CustomVoice
Features 9 premium preset timbres with granular style control. Perfect for applications requiring specific emotional delivery.
Qwen3-TTS-12Hz-1.7B-Base
The foundational engine for zero-shot cloning. Requires only 3 seconds of audio to replicate a voice. Ideal for fine-tuning.
0.6B Lightweight Series
High EfficiencyQwen3-TTS-12Hz-0.6B-CustomVoice
A faster, lighter version of the CustomVoice model. Includes the same 9 premium timbres but optimized for lower latency and resource usage.
Qwen3-TTS-12Hz-0.6B-Base
Efficient zero-shot cloning capabilities in a compact package. Perfect for edge devices or scenarios with limited compute budgets.
Easy Deployment: When using the qwen-tts package or vLLM, model weights are automatically downloaded based on the model name you select. No manual setup required.
Our Technology
Why Choose Qwen3-TTS?
Powered by the Qwen3-TTS-Tokenizer-12Hz multi-codebook speech encoder, our platform delivers SOTA performance.
High-Fidelity Reconstruction: Unlike traditional models, Qwen3-TTS utilizes a lightweight non-DiT architecture with a 12Hz tokenizer. This ensures efficient acoustic compression while preserving paralinguistic information like breath and ambient tone.
Dual-Track Modeling: Experience extreme low-latency streaming. The model can output the first audio packet after processing just a single character, with end-to-end latency as low as 97ms.
Intelligent Understanding: The model deeply integrates text semantic understanding, allowing it to adapt tone, rhythm, and emotion based on natural language instructions.
Key Features
Multilingual Support
Native support for Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
Zero-Shot Cloning
Clone any voice using just 3 seconds of reference audio with high speaker similarity (0.789 score).
Voice Design
Create new voices from scratch using natural language prompts describing age, gender, and personality.
Instruction Control
Control prosody, emotion, and style via text instructions (e.g., "speak sadly", "whisper").
Real-Time Streaming
Dual-Track hybrid architecture enables instant playback with minimal buffering.
Robust Text Handling
Handles complex text, special symbols, and mixed languages effortlessly.
How to Use Qwen3-TTS Online
Choose Your Mode
Select between Custom Voice for standard TTS, Voice Design to create a persona, or Voice Clone to replicate a voice.
Input Text & Config
Type the text you want the AI to speak. Optionally, add style instructions or upload reference audio.
Generate & Download
Click generate to process the audio in the cloud. Listen to the high-fidelity result and download it.
Official X Reviews on Qwen3-TTS
Qwen3-TTS is officially live. Qwen've open-sourced the full family, including VoiceDesign, CustomVoice, and Base, bringing high quality to the open community.
Frequently Asked Questions
Is Qwen3-TTS Online free to use?
Yes, Qwen3-TTS is an open-source project. Our online demo allows you to experience its capabilities for free. qwen3tts.art has launched all of its Qwen3-TTS models, including Voice Clone, Voice Design, and Text-to-Speech (Custom Voice). You can upgrade to a membership for the best voice generation experience.
What languages does Qwen3-TTS support?
Qwen3-TTS supports 10 languages: Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian. In the near future, Qwen3 may add more languages. Please stay tuned to our platform for the latest updates on Voice Model developments.
What is the difference between the 1.7B and 0.6B models?
The 1.7B model offers peak performance and complex instruction following, while the 0.6B model is optimized for efficiency and speed.
Can I use the generated audio for commercial purposes?
These TTS models are open-sourced by the Qwen team. These voice models are released under the Apache-2.0 license, so you can use them for commercial purposes.
How does Qwen3-TTS compare to other models?
In benchmarks, it outperforms MiniMax in voice design and shows higher speaker similarity than ElevenLabs in multilingual cloning tasks.
Qwen3-TTS Latest Updates
Qwen3 TTS Family is Now Open Sourced
Qwen3-TTS is now open source. Explore the 1.7B & 0.6B models featuring 3s voice cloning, <100ms latency, and advanced voice design capabilities.
Qwen3 TTS Install Guide
Discover Qwen3-TTS features and follow our step-by-step Qwen3 TTS install guide. Master real-time voice cloning and custom speech generation with Python code.
Qwen3 ASR is Now Open Sourced
Qwen3-ASR is now open source. Unlock the 1.7B & 0.6B models featuring 52-language support, precise forced alignment, and robust streaming inference.